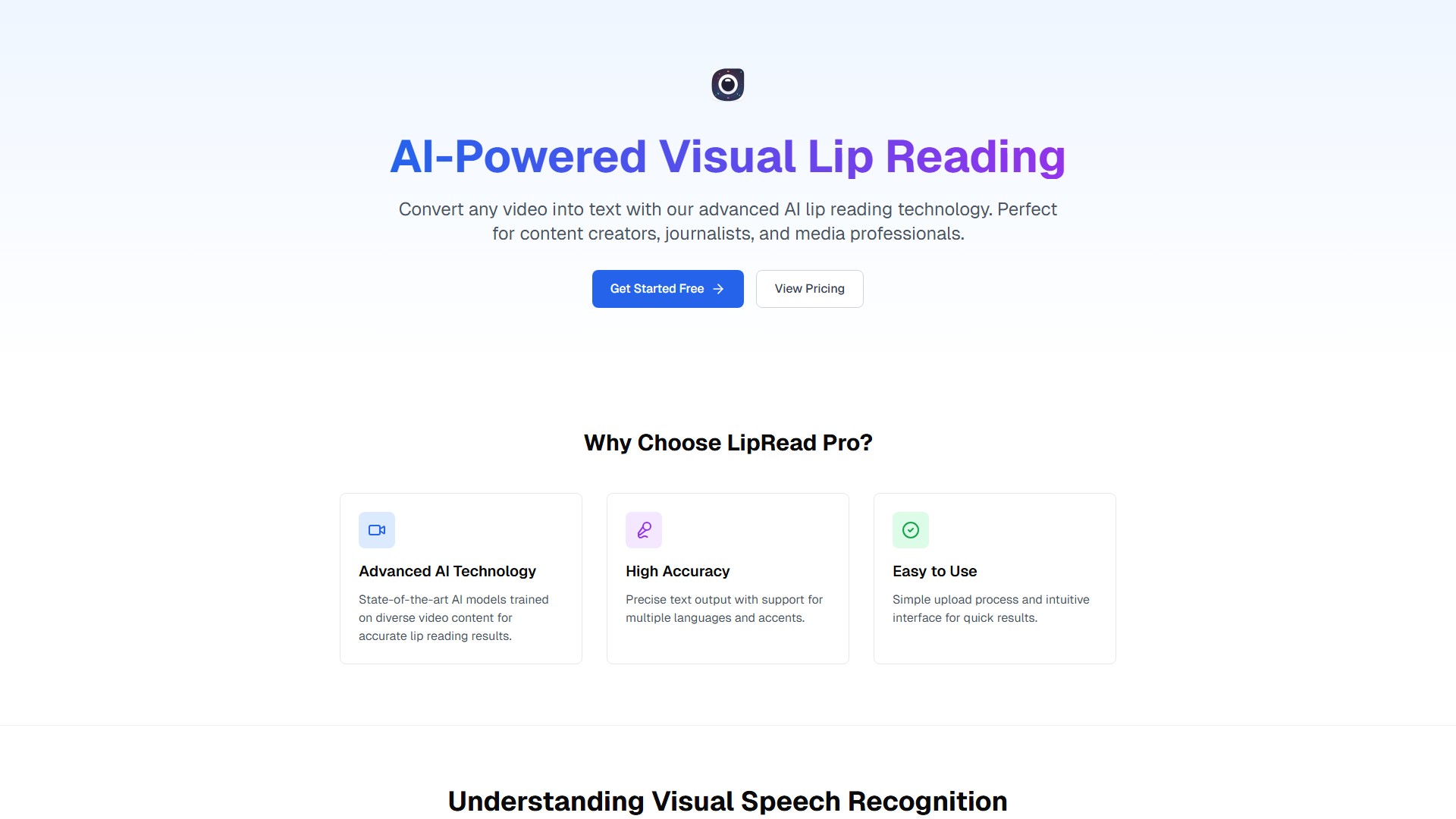
将任何视频中的唇部动作转换为准确的文本内容。
视觉语音识别(VSR)使用深度学习分析视频内容中的唇部动作和面部表情,并以高准确率将其转换为文本。
内容创作者、记者、媒体专业人士。
提供免费试用。具体的定价方案需访问定价页面查看详情。
访问量 43.26K 计价模式 Free TrialPaid
访问量 0 计价模式 FreemiumPaid
访问量 0 计价模式 Contact for PricingFreeFreemiumFree TrialPaid