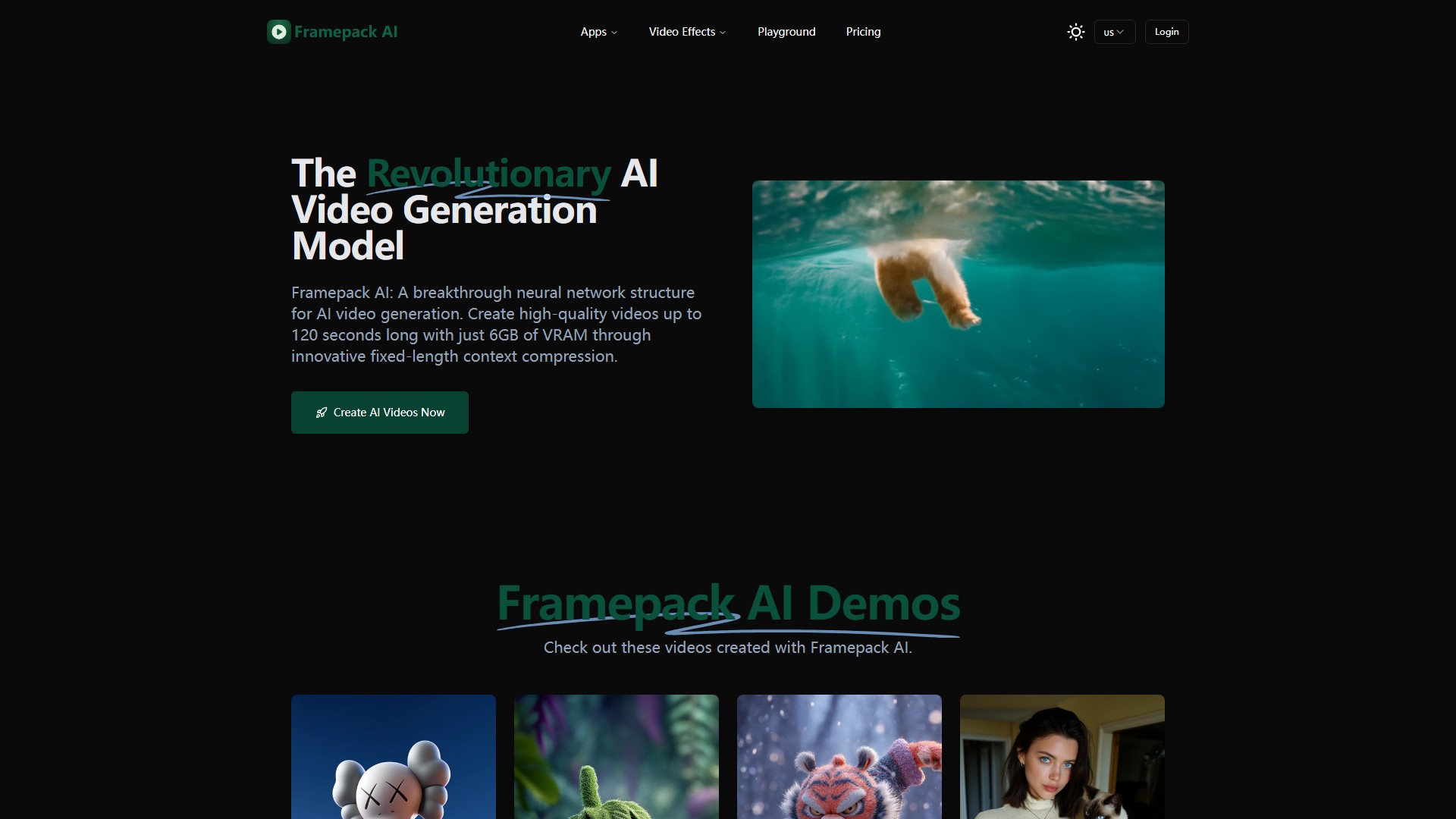
Q: Framepack AI是什么? A: 专业的神经网络结构,使用'下一帧预测'技术进行AI视频生成,通过压缩输入上下文信息到固定长度,使计算负载独立于视频长度。
Q: 硬件要求是什么? A: 需要至少6GB显存的NVIDIA RTX 30XX、40XX或50XX系列GPU,支持Windows和Linux系统。
Q: 能生成多长的视频? A: 根据硬件配置和优化技术,可生成60-120秒30fps的高质量视频。
Q: 与其他视频生成模型有何不同? A: 主要创新是固定长度上下文压缩,避免传统模型面临的上下文长度随时间线性增长问题,大幅降低显存需求和计算成本。
Q: 是否开源? A: 是的,由ControlNet创作者Lvmin Zhang和斯坦福大学教授Maneesh Agrawala开发,代码和模型在GitHub上公开可用。
访问量 250.27K 计价模式
访问量 0 计价模式 FreemiumPaid

访问量 0 计价模式 Contact for PricingFreePaid